
Publish and reproduce the work¶
Finally we have finished the analysis and the writeup, and now it is time to publish our work somewhere. For this case we choose to publish the toy workflow as webpages linked to the Github repository, but the steps and points we consider here also apply to different publishing scenarios, no matter whether the material is peer-reviewed or not.
It is also important to advertise/publicize our work. One key point we have to keep in mind is how easy the other researchers can access and reproduce the entire workflow and results. There are at least two benefits by maximizing the reproducibility of the work:
It allows readers to quickly understand our work, so we can pay less effort to advertise it.
The other researchers can easily build new analysis on top of our work, advancing our understanding of the Earth with a fast rate.
In this section, we will introduce what we have done for publicizing and reproducing our glacier crevass analysis.
Manage the entire work, not only the final paper¶
The final, peer-reviewed journal paper might be something we want to achieve at last. Besides this polished, concentrated piece of writing, it requires more to give to readers for them to understand and follow details of our work, including but not limited to:
Source and derived data
Code and workflow for generate results, figures, and tables
Documentation (user guide, data availability statement, code comments, etc.)
References, bibliogrpahy, cross-links, or something else for readers to get more information if needed
The geosicence community has done a good job for some of them. For example, a good portion of us use EndNote, Mendeley, or Zotero to manage references and citations. For the other part on the list, we are just starting to be aware of them.
Zenodo for data¶
Many publishers with a focus of geoscience studies have proposed some guidelines for open and share data and software (for example, here are AGU’s FAIR data policy and guidelines). Zenodo is now gradually becoming a popular choice for data and software hosting as an upload batch to Zenodo can be assigned with a DOI and can be linked to the associated publication(s).
Github for code and documentation¶
For projects that are activately updating, hosting code and documentation on a Github repository has several advantages. Beside the reader accessibliy, we can also deploy some automated workflows to update web-hosted documents and save time (see below). The repository of this glacier crevass analysis can be found here. The subsections below are some important points we did for creating the repository.
1. Apply a license¶
A license might not look critical to this research project, but it does tell the audience what they can do with the content presented here. We use an MIT license here, which is a permissive license and grants users ample room to use, reuse, and modify this work.
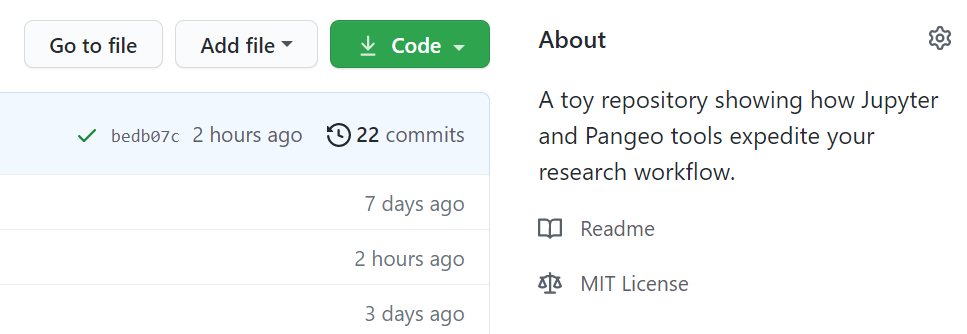
Fig. 3 Our ICESat-2 sees glacier crevasses project is released with an MIT license.¶
2. Make Github Actions¶
Whenever there is an update being pushed to this repository, the corrsponding html pages will be updated automatically. The tool behind the scenes is Github Actions, which runs workflow stored in the .github/workflows folder. For this crevasse analysis, we write a workflow that installs necessary packages (for executing Notebooks), builds Jupyter Book htmls, and deploy the htmls to Github pages (the links you are reading right now).
To install necessary packages, we make an environment.yml file in the repo specifying tools used in the workflow. You can view this file here for ideas about its format. We will need the same file to run Binder as well (see below).
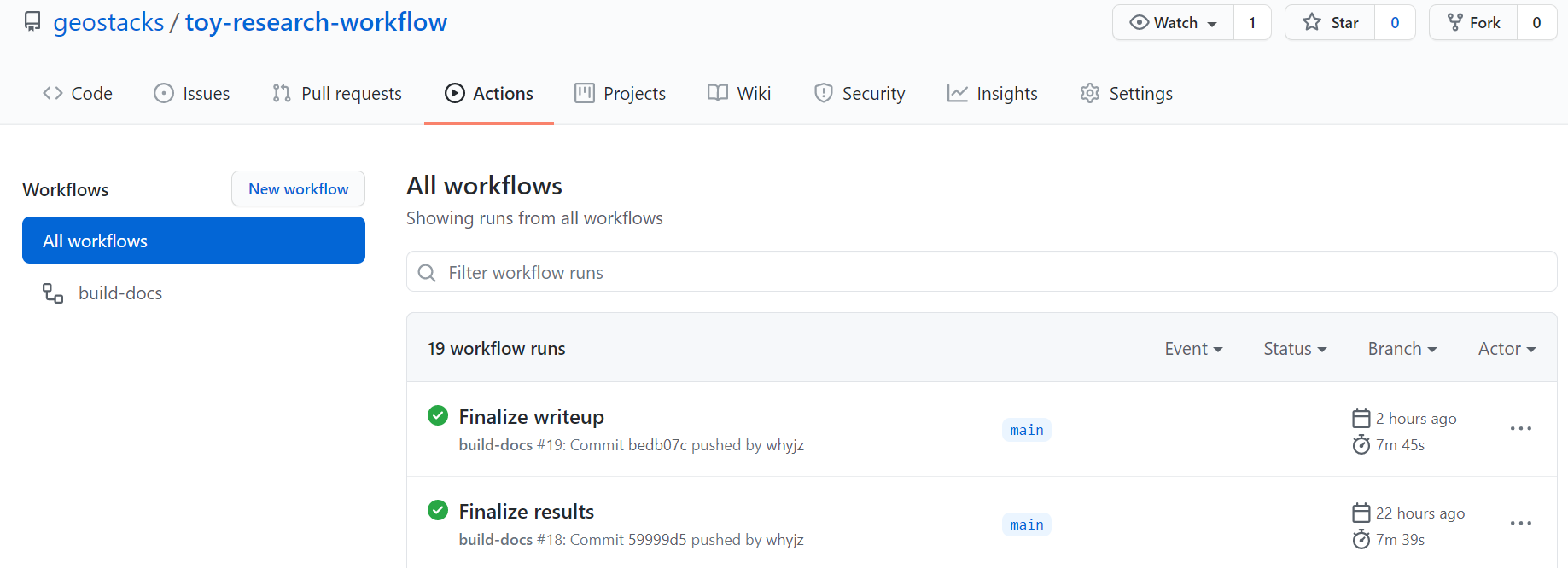
Fig. 4 Github Actions execute the build-docs workflow automatically after each push.¶
Use Binder to share and reproduce the work in just one click¶
To make this workflow as reproducive as possible, we use a cloud-based service called Binder. The Binder service can turn a public repository into a live server where you can execute Notebooks, Python files, and other contents, as long as we provide a list of required packages (that is, environment.yml).
We can use Binder independently for single or more Notebooks in a repository, as we have seen in many EarthCube submissions. We can also just use Jupyter Book to complie the work since Jupyter Book integrates the Binder service well. If the source file of a Jupyter Book page is Notebook, there will be a Binder link in the upper right of the page (Figure For each Notebook page, the Binder link allows readers to execute it.) for readers to directly execute it.

Fig. 5 For each Notebook page, the Binder link allows readers to execute it.¶
Hence, sharing and reproducing this Negribreen crevasse analysis can’t be made easier than that.